chevron_left
Back to "Mathematics > Hypercubes and Hyperspheres"
Continue to "Mathematics > Prime Sets II"
chevron_right07-10-2003
Prime quantities and approximations
Prime numbers have been a mystery for mathematicians for thousands of years - so far only relatively superficial properties have been found. Neither is there a formula to calculate the x-th prime number, nor is there an exact way to calculate the amount of primes between 1 and x without checking all numbers. Of course, by "checking all numbers" I mean only all numbers up to x, and also only those ending with 1, 3, 7 or 9 - because except for 5 there is no prime number ending with 5.
However, mathematics is gradually making progress in both respects. For example, the mathematician Leonhard Euler, who discovered the probably most versatile mathematical constant e=2.71828..., laid a foundation for the estimation of the amount of prime numbers. This number later enabled the mathematician Carl Friedrich Gauss to find out that the amount of prime numbers between 1 and x can be approximately described by the fraction x/lnx. LN is the natural logarithm, i.e. the logarithm to the base e, which is the inverse function to e^x. e to the power of which number gives x? The answer is ln(x), simplified written as lnx or "ln x", which is pronounced as "the logarithm of x to the base e" or "the natural logarithm of x".
But how did this formula x/lnx come into being? The following is a small table. p(x) represents the amount of prime numbers up to the number x - so it has nothing to do with the circle-related number p. x/p(x) is the rounded factor, which shows the ratio between numbers and prime numbers up to the number x - the larger this factor is, the more numbers there are, so the smaller the proportion of prime numbers. The column on the right contains in each case the slope of the second to the last column, of the current row to the next row.
The slope value of the right column starts at 1.5, shoots up to 2.31, gets lower again, and finally settles at a number very reminiscent of ln(10). Based on this finding, Gauss conjectured that the natural logarithm was related to the number of primes from 1 through x. Thus this formula was found
p(x) ~ x/lnx
In 1808, the mathematician Legendre, who had collected more extensive data on p(x), refined the original approximation. His version was:
p(x) ~ x/[ln(x) - 1,08366]
When x becomes larger, so-called chaotic oscillations occur in the true amount of prime numbers, which mathematicians possibly want to compensate by Riemann's Zeta function in order to obtain better approximations. From this consideration also a new approximation formula is already known, which needs noticeably more computing power than x/lnx however. The Zeta function, which is represented by the sign, consists of an infinite series that looks as follows: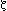 (z) = 1 + 1/(2^z) + 1/(3^z) + 1/(4^z) + ...
(z) = 1 + 1/(2^z) + 1/(3^z) + 1/(4^z) + ...
The Riemann approximation for the amount of primes, which contains the Zeta function of the same mathematician, reads as follows:
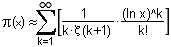
Let's call this approximation R(x) from now on, because both functions - approximation and Zeta function - were sent by Bernhard Riemann to the Berlin Academy of Science in November 1859.
Since I don't like giving up on such fascinating mathematical areas, I discovered a similarly accurate variant in May 2003 after some trial and error with previous formulas and a few ideas of my own - an idea that has a few advantages and unfortunately also disadvantages compared to R(x) - up to 10^9, the calculation error is very small and the calculation can be done quickly. At 10^10 the error increases noticeably - one of the disadvantages. Another disadvantage, to put the cards on the table, is that the computational effort becomes higher than that of R(x) from about 10^10. Only slightly at first, becoming more noticeable at higher numbers. However, this is only the case if one breaks off the respective infinite series with R(x), as soon as a further calculation has no more visible influence on the final result. If one wants higher accuracy, R(x) needs of course more time than the following formula of mine:
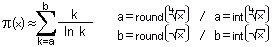
The initial value for k is therefore the fourth root of x. Leaving this root as it is unfortunately affects the accuracy of the whole formula - therefore the most recommended options are: either round it to the first decimal place or simply ignore all decimal places. So now we have our starting value for k, which has either no decimal place at all or a single decimal place. After each calculation of k/ln(k), k is increased by 1 and k/ln(k) is calculated with the now increased k. The next k/ln(k) is added to all previous ones. As soon as after adding 1 a value occurs at k, which is larger than the square root of x, then the approximation is finished. This final value, like the starting value, should in any case also be rounded to the first decimal place - or, alternatively, one simply ignores all decimal places, without any rounding. All calculated k/ln(k) added together now show very precisely how many prime numbers between 1 and x exist. I am especially proud of the result 1229.03 at x=10000, because there are indeed 1229 prime numbers between 1 and 10000.
Now one might assume that the remaining calculation error lies in the partly extreme rounding of start and end values. A philosophically gifted friend also encouraged me to look into this - so I can now reassure everyone: if you calculate the same approximation without any rounding, the error is not really less on average. However, you can get somewhat more accurate results if you don't round to the ones place (before the decimal point), but to the tenths place, i.e. the first digit after the decimal point. Unfortunately, I can't really answer yet why this is the case - the rounding is probably just one of the error sources, and there are several more factors to consider if you want to use it to get a more accurate approximation. Or it is pure coincidence :-)
Another approximation for the amount of primes is a logarithmic integral, hereafter called Li(x), which looks relatively similar to my approximation version:
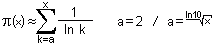
Again a formula with the sum sign. In the generally known version, the first value for k is always two, which has the simple background that 1/ln(k) would result in an invalid division by 0, if one starts with 1. However, I noticed that the value which can be calculated by this is always a little bit higher than the true amount of primes in the respective range. So I tried around a bit and finally ended up with a number which had already originally inspired the mathematician Gauss to use the term x/ln(x): the natural logarithm of 10. Only in this case it represents the root of x, which stands for the starting value - so we don't take the square root of x, but about the 2.3rd root. This can also be written as:
a = x^[1 / ln(10)]
This new initial value for Li(x) does not reduce the total effort by much, which is considerably higher than with my variant - but the accuracy is visibly increased in any case.
In the following table I would like to show how accurate or less accurate the approximations mentioned so far are in comparison:
- in the first column there is only n, which is used in the formulas in the form of 10^n, i.e. it represents the number of zeros after the 1 (10^5 = 100000).
- p(10^n) stands for the true amount of primes between 1 and x.
- L(n) stands for (10^n)/(ln(10^n) - 1,08366), which is Legendre's approximation for the amount of primes.
- N(10^n) stands for my own approximation, N for my last name Neumann, with tenth-rounding in the starting values.
- R(10^n) stands for Riemanns approximation.
- all approximations are rounded to the first digit BEFORE the decimal point, so no decimal places are displayed.
The first approximation, i.e. the x/lnx-variant of Légendre, is by far the fastest of the three, because it contains only very few calculation steps in comparison, even if one considered the calculation operation LN in detail - unfortunately, it is also the least accurate approximation among the three formulas. The approximation R(x) is the second fastest from n=8, but needs the most memory capacity, because it uses extremely high numbers for its calculations. Many generally available programs are unfortunately not capable of such a performance - in this case N(x) would then provide a relatively good substitute. It is slower than R(x) from n=8 onwards, but it uses visibly lower numbers, so it does not need a lot of memory. Unfortunately, I do not own a computational program that is able to achieve the accuracy necessary for R(x), so I gladly accept the help of others. In this respect I would like to thank Eugen Bauhof, Rainer Plugge and Markus M. from the forum of www.wissenschaft-online.de for their help regarding the approximation function: Thank you! :o)
The Légendre approximation is perfectly suitable to calculate an approximate value casually, but it now falls out of our table as the most inaccurate of the three approximations. So we can now additionally see how more or less precise the last mentioned approximation Li(x) is - with and without my small change.
The original version of Li(x) is completely unsuitable both in terms of accuracy and of speed - Légendre's approximation, which was excluded earlier, would be more suitable. The improved version of Li(x) is well suited up to about n=6 because of the accuracy, however, my approximation N(x) is faster in any case and, as said, starting from n=6 it is mostly more accurate even.
Since I am primarily concerned with the speed and optimization of the approximations, I was and am very glad about the e-mail from Mr. Wehmeier from the University of Paderborn. In his e-mail he pointed out to me, among other things, that my approximation can be replaced by an integral, which on average provides even more accurate solutions. Since the corresponding calculation needs much less computing power than my approximation in almost every case, I feel virtually forced to include it here and compare it. :-)
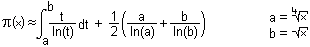
This approximation, let's call it Li_b(x), is now a little more complicated, but for practical applications it is in any case more useful than the other approximations mentioned here because of its higher computational speed.
Here is a comparison between the new formula Li_b(x), Riemann's approximation R(x) and my approximation N(x).
As you can see here, Li_b(x) does not quite reach the average accuracy of Riemann's approximation, which is unsurpassed so far. However, the integral approximation is both faster and mostly more accurate than my sum approximation and thus in any case much more suitable for practical applications, as long as one finds practical applications for prime sets... ;-)
However, mathematics is gradually making progress in both respects. For example, the mathematician Leonhard Euler, who discovered the probably most versatile mathematical constant e=2.71828..., laid a foundation for the estimation of the amount of prime numbers. This number later enabled the mathematician Carl Friedrich Gauss to find out that the amount of prime numbers between 1 and x can be approximately described by the fraction x/lnx. LN is the natural logarithm, i.e. the logarithm to the base e, which is the inverse function to e^x. e to the power of which number gives x? The answer is ln(x), simplified written as lnx or "ln x", which is pronounced as "the logarithm of x to the base e" or "the natural logarithm of x".
But how did this formula x/lnx come into being? The following is a small table. p(x) represents the amount of prime numbers up to the number x - so it has nothing to do with the circle-related number p. x/p(x) is the rounded factor, which shows the ratio between numbers and prime numbers up to the number x - the larger this factor is, the more numbers there are, so the smaller the proportion of prime numbers. The column on the right contains in each case the slope of the second to the last column, of the current row to the next row.
| 10^n = x | p(x) | F(n) = x / p(x) | G(n) = F(n+1) - F(n) |
| 10 | 04 | 2,50 | 1,50000000 |
| 100 | 025 | 4,00 | 1,95238095 |
| 1.000 | 0.168 | 5,95 | 2,18431555 |
| 10.000 | 01.229 | 8,14 | 2,28865796 |
| 100.000 | 009.592 | 10,43 | 2,31382361 |
| 1.000.000 | 0.078.498 | 12,74 | 2,30794199 |
| 10.000.000 | 00.664.579 | 15,05 | 2,30960667 |
| 100.000.000 | 005.761.455 | 17,36 | 2,30991040 |
| 1.000.000.000 | 0.050.847.534 | 19,67 | 2,30884869 |
| 10.000.000.000 | 00.455.052.511 | 21,98 | 2,30782379 |
| 100.000.000.000 | 004.118.054.813 | 24,28 | 2,30683982 |
| 1.000.000.000.000 | 0.037.607.912.018 | 26,59 | 2,30611136 |
| 10.000.000.000.000 | 00.346.065.536.839 | 28,90 | 2,30555435 |
| 100.000.000.000.000 | 003.204.941.750.802 | 31,20 | 2,30511715 |
| ln(10) = 2,30258509 | |||
The slope value of the right column starts at 1.5, shoots up to 2.31, gets lower again, and finally settles at a number very reminiscent of ln(10). Based on this finding, Gauss conjectured that the natural logarithm was related to the number of primes from 1 through x. Thus this formula was found
p(x) ~ x/lnx
In 1808, the mathematician Legendre, who had collected more extensive data on p(x), refined the original approximation. His version was:
p(x) ~ x/[ln(x) - 1,08366]
When x becomes larger, so-called chaotic oscillations occur in the true amount of prime numbers, which mathematicians possibly want to compensate by Riemann's Zeta function in order to obtain better approximations. From this consideration also a new approximation formula is already known, which needs noticeably more computing power than x/lnx however. The Zeta function, which is represented by the sign, consists of an infinite series that looks as follows:
(z) = 1 + 1/(2^z) + 1/(3^z) + 1/(4^z) + ...
The Riemann approximation for the amount of primes, which contains the Zeta function of the same mathematician, reads as follows:
Let's call this approximation R(x) from now on, because both functions - approximation and Zeta function - were sent by Bernhard Riemann to the Berlin Academy of Science in November 1859.
Since I don't like giving up on such fascinating mathematical areas, I discovered a similarly accurate variant in May 2003 after some trial and error with previous formulas and a few ideas of my own - an idea that has a few advantages and unfortunately also disadvantages compared to R(x) - up to 10^9, the calculation error is very small and the calculation can be done quickly. At 10^10 the error increases noticeably - one of the disadvantages. Another disadvantage, to put the cards on the table, is that the computational effort becomes higher than that of R(x) from about 10^10. Only slightly at first, becoming more noticeable at higher numbers. However, this is only the case if one breaks off the respective infinite series with R(x), as soon as a further calculation has no more visible influence on the final result. If one wants higher accuracy, R(x) needs of course more time than the following formula of mine:
The initial value for k is therefore the fourth root of x. Leaving this root as it is unfortunately affects the accuracy of the whole formula - therefore the most recommended options are: either round it to the first decimal place or simply ignore all decimal places. So now we have our starting value for k, which has either no decimal place at all or a single decimal place. After each calculation of k/ln(k), k is increased by 1 and k/ln(k) is calculated with the now increased k. The next k/ln(k) is added to all previous ones. As soon as after adding 1 a value occurs at k, which is larger than the square root of x, then the approximation is finished. This final value, like the starting value, should in any case also be rounded to the first decimal place - or, alternatively, one simply ignores all decimal places, without any rounding. All calculated k/ln(k) added together now show very precisely how many prime numbers between 1 and x exist. I am especially proud of the result 1229.03 at x=10000, because there are indeed 1229 prime numbers between 1 and 10000.
Now one might assume that the remaining calculation error lies in the partly extreme rounding of start and end values. A philosophically gifted friend also encouraged me to look into this - so I can now reassure everyone: if you calculate the same approximation without any rounding, the error is not really less on average. However, you can get somewhat more accurate results if you don't round to the ones place (before the decimal point), but to the tenths place, i.e. the first digit after the decimal point. Unfortunately, I can't really answer yet why this is the case - the rounding is probably just one of the error sources, and there are several more factors to consider if you want to use it to get a more accurate approximation. Or it is pure coincidence :-)
Another approximation for the amount of primes is a logarithmic integral, hereafter called Li(x), which looks relatively similar to my approximation version:
Again a formula with the sum sign. In the generally known version, the first value for k is always two, which has the simple background that 1/ln(k) would result in an invalid division by 0, if one starts with 1. However, I noticed that the value which can be calculated by this is always a little bit higher than the true amount of primes in the respective range. So I tried around a bit and finally ended up with a number which had already originally inspired the mathematician Gauss to use the term x/ln(x): the natural logarithm of 10. Only in this case it represents the root of x, which stands for the starting value - so we don't take the square root of x, but about the 2.3rd root. This can also be written as:
a = x^[1 / ln(10)]
This new initial value for Li(x) does not reduce the total effort by much, which is considerably higher than with my variant - but the accuracy is visibly increased in any case.
In the following table I would like to show how accurate or less accurate the approximations mentioned so far are in comparison:
- in the first column there is only n, which is used in the formulas in the form of 10^n, i.e. it represents the number of zeros after the 1 (10^5 = 100000).
- p(10^n) stands for the true amount of primes between 1 and x.
- L(n) stands for (10^n)/(ln(10^n) - 1,08366), which is Legendre's approximation for the amount of primes.
- N(10^n) stands for my own approximation, N for my last name Neumann, with tenth-rounding in the starting values.
- R(10^n) stands for Riemanns approximation.
- all approximations are rounded to the first digit BEFORE the decimal point, so no decimal places are displayed.
| n | p(10^n) | L(10^n) | N(10^n) | R(10^n) |
| 1 | 4 | 8 | 6 | 4 |
| 2 | 25 | 28 | 24 | 25 |
| 3 | 168 | 172 | 170 | 167 |
| 4 | 1.229 | 1.231 | 1.229 | 1.226 |
| 5 | 9.592 | 9.588 | 9.566 | 9.586 |
| 6 | 78.498 | 78.543 | 78.469 | 78.526 |
| 7 | 664.579 | 665.140 | 664.629 | 664.666 |
| 8 | 5.761.455 | 5.768.004 | 5.761.517 | 5.761.551 |
| 9 | 50.847.534 | 50.917.518 | 50.847.417 | 50.847.554 |
| 10 | 455.052.511 | 455.743.002 | 455.043.408 | 455.050.454 |
| 11 | 4.118.054.813 | 4.124.599.873 | 4.118.039.927 | 4.118.052.541 |
| 12 | 37.607.912.018 | 37.668.527.580 | 37.607.907.918 | 37.607.910.542 |
| 13 | 346.065.536.839 | 346.621.099.395 | 346.065.447.633 | 346.065.531.065 |
| 14 | 3.204.941.750.802 | 3.210.012.053.274 | 3.204.941.276.880 | 3.204.941.731.601 |
| 15 | 29.844.570.422.669 | 29.890.794.579.819 | 29.844.570.069.567 | 29.844.570.495.886 |
The first approximation, i.e. the x/lnx-variant of Légendre, is by far the fastest of the three, because it contains only very few calculation steps in comparison, even if one considered the calculation operation LN in detail - unfortunately, it is also the least accurate approximation among the three formulas. The approximation R(x) is the second fastest from n=8, but needs the most memory capacity, because it uses extremely high numbers for its calculations. Many generally available programs are unfortunately not capable of such a performance - in this case N(x) would then provide a relatively good substitute. It is slower than R(x) from n=8 onwards, but it uses visibly lower numbers, so it does not need a lot of memory. Unfortunately, I do not own a computational program that is able to achieve the accuracy necessary for R(x), so I gladly accept the help of others. In this respect I would like to thank Eugen Bauhof, Rainer Plugge and Markus M. from the forum of www.wissenschaft-online.de for their help regarding the approximation function: Thank you! :o)
The Légendre approximation is perfectly suitable to calculate an approximate value casually, but it now falls out of our table as the most inaccurate of the three approximations. So we can now additionally see how more or less precise the last mentioned approximation Li(x) is - with and without my small change.
| n | p(10^n) | Li(10^n) original | Li(10^n) verändert | N(10^n) |
| 1 | 4 | 6 | 5 | 6 |
| 2 | 25 | 30 | 25 | 24 |
| 3 | 168 | 177 | 168 | 170 |
| 4 | 1.229 | 1.246 | 1.227 | 1.229 |
| 5 | 9.592 | 9.630 | 9.590 | 9.566 |
| 6 | 78.498 | 78.627 | 78.541 | 78.469 |
| 7 | 664.579 | 664.918 | 664.727 | 664.629 |
| 8 | 5.761.455 | 5.762.209 | 5.761.769 | 5.761.517 |
| 9 | 50.847.534 | 50.849.235 | 50.848.197 | 50.847.417 |
| 10 | 455.052.511 | 455.055.614 | 455.053.122 | 455.043.408 |
| 11 | 4.118.054.813 | 4.118.066.400 | 4.118.060.329 | 4.118.039.927 |
| 12 | 37.607.912.018 | 37.607.950.281 | 37.607.935.321 | 37.607.907.918 |
| 13 | 346.065.536.839 | 346.065.645.810 | 346.065.608.612 | 346.065.447.633 |
| 14 | 3.204.941.750.802 | 3.204.942.065.692 | 3.204.941.972.500 | 3.204.941.276.880 |
| 15 | 29.844.570.422.669 | 29.844.571.475.287 | 29.844.571.240.332 | 29.844.570.069.567 |
The original version of Li(x) is completely unsuitable both in terms of accuracy and of speed - Légendre's approximation, which was excluded earlier, would be more suitable. The improved version of Li(x) is well suited up to about n=6 because of the accuracy, however, my approximation N(x) is faster in any case and, as said, starting from n=6 it is mostly more accurate even.
Since I am primarily concerned with the speed and optimization of the approximations, I was and am very glad about the e-mail from Mr. Wehmeier from the University of Paderborn. In his e-mail he pointed out to me, among other things, that my approximation can be replaced by an integral, which on average provides even more accurate solutions. Since the corresponding calculation needs much less computing power than my approximation in almost every case, I feel virtually forced to include it here and compare it. :-)
This approximation, let's call it Li_b(x), is now a little more complicated, but for practical applications it is in any case more useful than the other approximations mentioned here because of its higher computational speed.
Here is a comparison between the new formula Li_b(x), Riemann's approximation R(x) and my approximation N(x).
| n | p(10^n) | Li_b(10^n) | R(10^n) | N(10^n) |
| 1 | 4 | 7 | 4 | 6 |
| 2 | 25 | 28 | 25 | 24 |
| 3 | 168 | 170 | 167 | 170 |
| 4 | 1.229 | 1.229 | 1.226 | 1.229 |
| 5 | 9.592 | 9.589 | 9.586 | 9.566 |
| 6 | 78.498 | 78.527 | 78.526 | 78.469 |
| 7 | 664.579 | 664.659 | 664.666 | 664.629 |
| 8 | 5.761.455 | 5.761.517 | 5.761.551 | 5.761.517 |
| 9 | 50.847.534 | 50.847.344 | 50.847.554 | 50.847.417 |
| 10 | 455.052.511 | 455.050.352 | 455.050.454 | 455.043.408 |
| 11 | 4.118.054.813 | 4.118.051.590 | 4.118.052.541 | 4.118.039.927 |
| 12 | 37.607.912.018 | 37.607.909.063 | 37.607.910.542 | 37.607.907.918 |
| 13 | 346.065.536.839 | 346.065.542.248 | 346.065.531.065 | 346.065.447.633 |
| 14 | 3.204.941.750.802 | 3.204.941.934.260 | 3.204.941.731.601 | 3.204.941.276.880 |
| 15 | 29.844.570.422.669 | 29.844.572.751.595 | 29.844.570.495.886 | 29.844.570.069.567 |
As you can see here, Li_b(x) does not quite reach the average accuracy of Riemann's approximation, which is unsurpassed so far. However, the integral approximation is both faster and mostly more accurate than my sum approximation and thus in any case much more suitable for practical applications, as long as one finds practical applications for prime sets... ;-)